Load Data and look at data structure
shipped_raw <- read.csv("POS Output v3.csv",stringsAsFactors=FALSE,fileEncoding="UTF-8-BOM")
shipped_data <- shipped_raw
kable(str(shipped_data))
## 'data.frame': 7195307 obs. of 15 variables:
## $ Date.Fiscal.Year. : int 2018 2018 2018 2018 2018 2018 2018 2018 2018 2018 ...
## $ Date.Fiscal.Week. : int 45 45 45 45 45 43 43 43 43 43 ...
## $ Product.Sales.Code. : chr "LUB10" "LUB10" "LUB10" "LUB10" ...
## $ Product.Macrocategory.: chr "Foliage" "Foliage" "Foliage" "Foliage" ...
## $ Product.Genus. : chr "Calathea" "Calathea" "Calathea" "Calathea" ...
## $ X.Sales_Qty. : int 114 103 25 16 18 2 20 66 62 14 ...
## $ X.Shipped_Qty. : int 0 0 10 NA 0 NA NA 25 30 50 ...
## $ X.COGS. : num 890 805 195 125 143 ...
## $ Customer.Customer. : chr "Lowe's" "Lowe's" "Lowe's" "Lowe's" ...
## $ Store.Macro.Region. : chr "SOUTHEAST" "SOUTHEAST" "SOUTHEAST" "SOUTHCENTRAL" ...
## $ Store.Region. : chr "Region 2" "Region 2" "Region 2" "Region 7" ...
## $ Store.Sub.Region. : chr "8" "7" "8.1" "9" ...
## $ Product.Category. : chr "FLG - Large Indoor" "FLG - Large Indoor" "FLG - Large Indoor" "FLG - Large Indoor" ...
## $ X.Sales_Amt. : num 1139 803 221 177 133 ...
## $ X.LY_Shipped_Qty. : int NA NA NA NA NA NA NA 15 38 NA ...
Check null values by column
colSums(sapply(shipped_data,is.na))
## Date.Fiscal.Year. Date.Fiscal.Week. Product.Sales.Code.
## 50159 50159 0
## Product.Macrocategory. Product.Genus. X.Sales_Qty.
## 0 0 428379
## X.Shipped_Qty. X.COGS. Customer.Customer.
## 5988538 436720 0
## Store.Macro.Region. Store.Region. Store.Sub.Region.
## 0 0 0
## Product.Category. X.Sales_Amt. X.LY_Shipped_Qty.
## 0 428379 5938308
Drop rows that have null values for Year/Week and check nulls again
shipped_data <- shipped_data[!is.na(shipped_data$Date.Fiscal.Year), ]
colSums(sapply(shipped_data,is.na))
## Date.Fiscal.Year. Date.Fiscal.Week. Product.Sales.Code.
## 0 0 0
## Product.Macrocategory. Product.Genus. X.Sales_Qty.
## 0 0 378220
## X.Shipped_Qty. X.COGS. Customer.Customer.
## 5938401 386561 0
## Store.Macro.Region. Store.Region. Store.Sub.Region.
## 0 0 0
## Product.Category. X.Sales_Amt. X.LY_Shipped_Qty.
## 0 378220 5938308
Find the number of rows that Shipped Quantity are null for both this year and the prior year.
nrow(shipped_data[is.na(shipped_data$X.Shipped_Qty.) & is.na(shipped_data$X.LY_Shipped_Qty.),])
## [1] 5217147
Find the percentage of rows that are missing for both year and last year as a percent of missing data
nrow(shipped_data[is.na(shipped_data$X.Shipped_Qty.) & is.na(shipped_data$X.LY_Shipped_Qty.),])/nrow(shipped_data[is.na(shipped_data$X.Shipped_Qty.),])
## [1] 0.8785441
It looks like the Shipped Quantity data was joined to a larger data set which resulted in nulls for those combinations of columns that didn’t join 1 for 1.
For now I will just replace the rows with null values with zeroes in order to keep the additional information stored in these rows.
shipped_data$X.Shipped_Qty.[is.na(shipped_data$X.Shipped_Qty.)] <- 0
shipped_data$X.LY_Shipped_Qty.[is.na(shipped_data$X.LY_Shipped_Qty.)] <- 0
#Find the number of rows that are missing both Sales Qty and Sales Amount. Turns out to be the same rows.
nrow(shipped_data[is.na(shipped_data$X.Sales_Qty.) & is.na(shipped_data$X.Sales_Amt.),])
## [1] 378220
Find the number of rows that are missing both Sales Qty and COGS. It seems there are a few additional rows missing for COGS, but for the most part they are both missing the same rows.
nrow(shipped_data[is.na(shipped_data$X.Sales_Qty.) & is.na(shipped_data$X.COGS.),])
## [1] 378220
nrow(shipped_data[is.na(shipped_data$X.Sales_Qty.) & is.na(shipped_data$X.COGS.),])/nrow(shipped_data[is.na(shipped_data$X.COGS.),])
## [1] 0.9784226
For now I will just change all these nulls to zero
shipped_data[is.na(shipped_data)] <- 0
Create a date variable to view time series data. First, I have to add a zero in front of numbers 1 through 9 in order to be able to convert it correctly.
shipped_data$Date.Fiscal.Week.[shipped_data$Date.Fiscal.Week.<10] <- paste0("0",shipped_data$Date.Fiscal.Week.[shipped_data$Date.Fiscal.Week.<10])
shipped_data$Date <- paste(shipped_data$Date.Fiscal.Year.,shipped_data$Date.Fiscal.Week.,sep = "-")
Change variables to correct data type
rapply(shipped_data,function(x)length(unique(x)))
## Date.Fiscal.Year. Date.Fiscal.Week. Product.Sales.Code.
## 6 53 5980
## Product.Macrocategory. Product.Genus. X.Sales_Qty.
## 11 542 8563
## X.Shipped_Qty. X.COGS. Customer.Customer.
## 7777 705971 3
## Store.Macro.Region. Store.Region. Store.Sub.Region.
## 8 14 18
## Product.Category. X.Sales_Amt. X.LY_Shipped_Qty.
## 45 861752 7776
## Date
## 310
act_factors <- names(shipped_data)[which(sapply(shipped_data,function(x)length(unique(x))<=100)|sapply(shipped_data,is.character))]
shipped_data[act_factors]<- lapply(shipped_data[act_factors],factor)
kable(str(shipped_data))
## 'data.frame': 7145148 obs. of 16 variables:
## $ Date.Fiscal.Year. : Factor w/ 6 levels "2015","2016",..: 4 4 4 4 4 4 4 4 4 4 ...
## $ Date.Fiscal.Week. : Factor w/ 53 levels "01","02","03",..: 45 45 45 45 45 43 43 43 43 43 ...
## $ Product.Sales.Code. : Factor w/ 5980 levels "","1.00ACHFRV",..: 4360 4360 4360 4360 4360 4360 4360 4360 4360 4360 ...
## $ Product.Macrocategory.: Factor w/ 11 levels "","Annuals","Blooming Tropicals",..: 6 6 6 6 6 6 6 6 6 6 ...
## $ Product.Genus. : Factor w/ 542 levels "","Acalypha",..: 79 79 79 79 79 79 79 79 79 79 ...
## $ X.Sales_Qty. : num 114 103 25 16 18 2 20 66 62 14 ...
## $ X.Shipped_Qty. : num 0 0 10 0 0 0 0 25 30 50 ...
## $ X.COGS. : num 890 805 195 125 143 ...
## $ Customer.Customer. : Factor w/ 3 levels "Home Depot","Lowe's",..: 2 2 2 2 2 2 2 2 2 2 ...
## $ Store.Macro.Region. : Factor w/ 8 levels "","N/A","NORTHEAST/CENTRAL",..: 6 6 6 5 5 6 5 6 6 6 ...
## $ Store.Region. : Factor w/ 14 levels "","N/A","Region 1",..: 7 7 7 12 12 7 12 7 7 7 ...
## $ Store.Sub.Region. : Factor w/ 18 levels "","#N/A","10",..: 14 13 15 16 14 12 16 13 14 15 ...
## $ Product.Category. : Factor w/ 45 levels "","ANS - Annuals",..: 23 23 23 23 23 23 23 23 23 23 ...
## $ X.Sales_Amt. : num 1139 803 221 177 133 ...
## $ X.LY_Shipped_Qty. : num 0 0 0 0 0 0 0 15 38 0 ...
## $ Date : Factor w/ 310 levels "2015-01","2015-02",..: 204 204 204 204 204 202 202 202 202 202 ...
Next, I need to aggregate all my data by the group of variables that I want to build a forecast.
shipped_agg <- shipped_data%>%
group_by(Date.Fiscal.Year.,Date.Fiscal.Week.,Customer.Customer.,Store.Sub.Region.,Product.Category.,Date)%>%
summarize(CY_Shipped = sum(X.Shipped_Qty.),
PY_Shipped = sum(X.LY_Shipped_Qty.),
COGS = sum(X.COGS.),
Sales_Qty = sum(X.Sales_Qty.),
Sales_Amt = sum(X.Sales_Amt.))
shipped_agg <- as.data.frame(shipped_agg)
Now I will inspect the data visually to see if anything abnormal catches my attention. First, I will inspect the Date variable I built earlier.
my_breaks <- seq(1,length(unique(shipped_agg$Date)),by=10)
ggplot(shipped_agg, aes(x = Date, y=CY_Shipped )) +
geom_bar(stat="identity") +
theme(axis.text.x = element_text(angle=65, vjust=0.6))+
scale_x_discrete(
breaks=levels(shipped_agg$Date)[my_breaks])
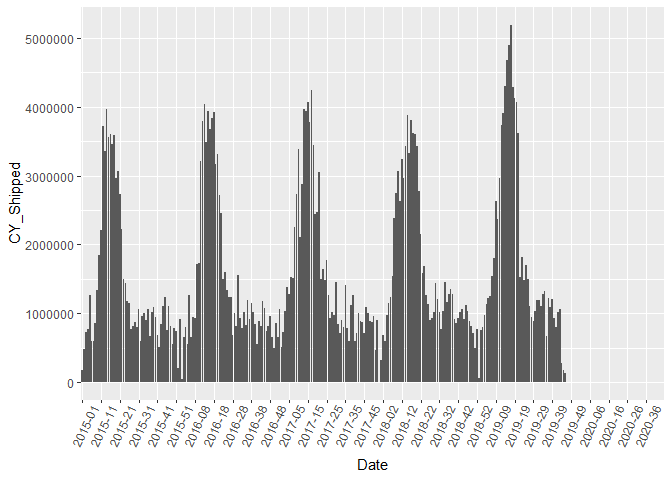
It’s hard to tell but it looks like we are missing data at the end of our Date range. Let’s check it out.
kable(shipped_agg%>%
group_by(Date)%>%
summarize(count=n(),
total = sum(CY_Shipped)))%>%
kable_styling() %>%
scroll_box(width = "500px", height = "200px")
| Date | count | total |
|---|---|---|
| 2015-01 | 1104 | 176314 |
| 2015-02 | 1025 | 475680 |
| 2015-03 | 1025 | 718916 |
| 2015-04 | 1034 | 768818 |
| 2015-05 | 1002 | 1265184 |
| 2015-06 | 1010 | 590407 |
| 2015-07 | 1040 | 589550 |
| 2015-08 | 1012 | 858661 |
| 2015-09 | 1024 | 1334855 |
| 2015-10 | 1022 | 1842944 |
| 2015-11 | 1034 | 2208468 |
| 2015-12 | 1043 | 3725464 |
| 2015-13 | 1059 | 3351484 |
| 2015-14 | 1074 | 3972595 |
| 2015-15 | 1080 | 3560389 |
| 2015-16 | 1100 | 3600819 |
| 2015-17 | 1117 | 3460655 |
| 2015-18 | 1117 | 3585257 |
| 2015-19 | 1120 | 2972426 |
| 2015-20 | 1129 | 3073670 |
| 2015-21 | 1125 | 2738860 |
| 2015-22 | 1112 | 2226360 |
| 2015-23 | 1118 | 1497526 |
| 2015-24 | 1112 | 1441926 |
| 2015-25 | 1128 | 1176588 |
| 2015-26 | 1106 | 1153929 |
| 2015-27 | 1114 | 776074 |
| 2015-28 | 1120 | 813471 |
| 2015-29 | 1128 | 868441 |
| 2015-30 | 1126 | 799869 |
| 2015-31 | 1110 | 1054440 |
| 2015-32 | 1111 | 594522 |
| 2015-33 | 1102 | 961393 |
| 2015-34 | 1114 | 1006242 |
| 2015-35 | 1095 | 900457 |
| 2015-36 | 1096 | 1056685 |
| 2015-37 | 1094 | 673180 |
| 2015-38 | 1102 | 1019734 |
| 2015-39 | 1106 | 1085217 |
| 2015-40 | 1106 | 943417 |
| 2015-41 | 1103 | 688043 |
| 2015-42 | 1107 | 508911 |
| 2015-43 | 1123 | 845380 |
| 2015-44 | 1111 | 1109528 |
| 2015-45 | 1115 | 1237812 |
| 2015-46 | 1106 | 756133 |
| 2015-47 | 1113 | 1096805 |
| 2015-48 | 1099 | 820066 |
| 2015-49 | 1096 | 553715 |
| 2015-50 | 1092 | 787819 |
| 2015-51 | 1096 | 734825 |
| 2015-52 | 1093 | 196751 |
| 2015-53 | 1090 | 922020 |
| 2016-01 | 1087 | 37166 |
| 2016-02 | 1087 | 651738 |
| 2016-03 | 1078 | 800541 |
| 2016-04 | 1053 | 547300 |
| 2016-05 | 1041 | 1266935 |
| 2016-06 | 1039 | 654449 |
| 2016-07 | 1022 | 943461 |
| 2016-08 | 1042 | 936292 |
| 2016-09 | 1049 | 1712264 |
| 2016-10 | 1063 | 1735562 |
| 2016-11 | 1066 | 3207721 |
| 2016-12 | 1092 | 3794607 |
| 2016-13 | 1091 | 4047196 |
| 2016-14 | 1105 | 3482648 |
| 2016-15 | 1122 | 3944928 |
| 2016-16 | 1141 | 3671362 |
| 2016-17 | 1154 | 3831141 |
| 2016-18 | 1154 | 3929474 |
| 2016-19 | 1159 | 3175573 |
| 2016-20 | 1168 | 3318393 |
| 2016-21 | 1168 | 2721664 |
| 2016-22 | 1168 | 2454912 |
| 2016-23 | 1166 | 1492611 |
| 2016-24 | 1172 | 1595307 |
| 2016-25 | 1171 | 1340768 |
| 2016-26 | 1166 | 1237812 |
| 2016-27 | 1160 | 1241507 |
| 2016-28 | 1160 | 676702 |
| 2016-29 | 1162 | 997467 |
| 2016-30 | 1153 | 813261 |
| 2016-31 | 1155 | 1560370 |
| 2016-32 | 1149 | 933326 |
| 2016-33 | 1140 | 782842 |
| 2016-34 | 1140 | 1013357 |
| 2016-35 | 1144 | 827290 |
| 2016-36 | 1149 | 1191819 |
| 2016-37 | 1146 | 908669 |
| 2016-38 | 1148 | 1151976 |
| 2016-39 | 1145 | 1014722 |
| 2016-40 | 1162 | 841974 |
| 2016-41 | 1142 | 547914 |
| 2016-42 | 1154 | 891777 |
| 2016-43 | 1157 | 806714 |
| 2016-44 | 1158 | 1171225 |
| 2016-45 | 1151 | 1077085 |
| 2016-46 | 1155 | 745533 |
| 2016-47 | 1149 | 812291 |
| 2016-48 | 1144 | 954714 |
| 2016-49 | 1140 | 647225 |
| 2016-50 | 1136 | 492482 |
| 2016-51 | 1131 | 857453 |
| 2016-52 | 1121 | 651736 |
| 2016-53 | 1116 | 1055611 |
| 2017-01 | 1104 | 507358 |
| 2017-02 | 1090 | 720732 |
| 2017-03 | 1077 | 1036649 |
| 2017-04 | 1085 | 1386120 |
| 2017-05 | 1083 | 1279695 |
| 2017-06 | 1094 | 1518976 |
| 2017-07 | 1084 | 1504738 |
| 2017-08 | 1104 | 2248669 |
| 2017-09 | 1103 | 2727403 |
| 2017-10 | 1096 | 3387558 |
| 2017-11 | 1116 | 2110491 |
| 2017-12 | 1116 | 2870845 |
| 2017-13 | 1102 | 3972457 |
| 2017-14 | 1117 | 3938165 |
| 2017-15 | 1145 | 4077093 |
| 2017-16 | 1147 | 3777769 |
| 2017-17 | 1164 | 4243976 |
| 2017-18 | 1147 | 3438270 |
| 2017-19 | 1164 | 2436509 |
| 2017-20 | 1150 | 2473438 |
| 2017-21 | 1144 | 3048414 |
| 2017-22 | 1139 | 1494081 |
| 2017-23 | 1128 | 1642386 |
| 2017-24 | 1138 | 1475733 |
| 2017-25 | 1127 | 1772163 |
| 2017-26 | 1127 | 1256671 |
| 2017-27 | 1118 | 927627 |
| 2017-28 | 1123 | 1020671 |
| 2017-29 | 1099 | 974178 |
| 2017-30 | 1109 | 1454635 |
| 2017-31 | 1107 | 843826 |
| 2017-32 | 1101 | 706822 |
| 2017-33 | 1114 | 898326 |
| 2017-34 | 1106 | 797766 |
| 2017-35 | 1107 | 1414836 |
| 2017-36 | 1101 | 785003 |
| 2017-37 | 1106 | 587984 |
| 2017-38 | 1092 | 1112209 |
| 2017-39 | 1101 | 1269767 |
| 2017-40 | 1094 | 602126 |
| 2017-41 | 1109 | 705206 |
| 2017-42 | 1099 | 1006947 |
| 2017-43 | 1098 | 891128 |
| 2017-44 | 1085 | 869906 |
| 2017-45 | 1081 | 705248 |
| 2017-46 | 1095 | 1094282 |
| 2017-47 | 1089 | 1001326 |
| 2017-48 | 1093 | 887124 |
| 2017-49 | 1084 | 872929 |
| 2017-50 | 1077 | 953712 |
| 2017-51 | 1056 | 463291 |
| 2017-52 | 1053 | 901877 |
| 2017-53 | 1038 | 0 |
| 2018-01 | 1060 | 325576 |
| 2018-02 | 1065 | 677086 |
| 2018-03 | 1054 | 594192 |
| 2018-04 | 1058 | 966243 |
| 2018-05 | 1048 | 1153339 |
| 2018-06 | 1059 | 1227725 |
| 2018-07 | 1068 | 1538160 |
| 2018-08 | 1074 | 2376844 |
| 2018-09 | 1082 | 2746304 |
| 2018-10 | 1077 | 3073629 |
| 2018-11 | 1090 | 2633524 |
| 2018-12 | 1088 | 3246326 |
| 2018-13 | 1081 | 2972258 |
| 2018-14 | 1084 | 3434567 |
| 2018-15 | 1091 | 3879499 |
| 2018-16 | 1082 | 3324898 |
| 2018-17 | 1106 | 3812500 |
| 2018-18 | 1098 | 3615039 |
| 2018-19 | 1113 | 3608791 |
| 2018-20 | 1126 | 3433668 |
| 2018-21 | 1118 | 2769745 |
| 2018-22 | 1105 | 2148625 |
| 2018-23 | 1102 | 1584570 |
| 2018-24 | 1111 | 1679610 |
| 2018-25 | 1106 | 1265381 |
| 2018-26 | 1101 | 1137080 |
| 2018-27 | 1101 | 901467 |
| 2018-28 | 1111 | 925816 |
| 2018-29 | 1099 | 1023262 |
| 2018-30 | 1095 | 1440600 |
| 2018-31 | 1088 | 1209750 |
| 2018-32 | 1089 | 1021708 |
| 2018-33 | 1105 | 766932 |
| 2018-34 | 1087 | 1035260 |
| 2018-35 | 1085 | 1446093 |
| 2018-36 | 1078 | 1162404 |
| 2018-37 | 1078 | 1282269 |
| 2018-38 | 1079 | 1345707 |
| 2018-39 | 1082 | 1284394 |
| 2018-40 | 1080 | 920550 |
| 2018-41 | 1076 | 857666 |
| 2018-42 | 1076 | 922532 |
| 2018-43 | 1074 | 1017598 |
| 2018-44 | 1069 | 1056534 |
| 2018-45 | 1069 | 915206 |
| 2018-46 | 1063 | 1117478 |
| 2018-47 | 1058 | 1032044 |
| 2018-48 | 1060 | 879955 |
| 2018-49 | 1052 | 813069 |
| 2018-50 | 1050 | 715880 |
| 2018-51 | 1047 | 493746 |
| 2018-52 | 1057 | 764003 |
| 2018-53 | 1044 | 57252 |
| 2019-01 | 1048 | 747982 |
| 2019-02 | 1048 | 794494 |
| 2019-03 | 1050 | 975622 |
| 2019-04 | 1052 | 1129077 |
| 2019-05 | 1053 | 1220011 |
| 2019-06 | 1045 | 1253905 |
| 2019-07 | 1044 | 1541032 |
| 2019-08 | 1049 | 1803261 |
| 2019-09 | 1051 | 2636057 |
| 2019-10 | 1044 | 2370363 |
| 2019-11 | 1047 | 2961700 |
| 2019-12 | 1049 | 3730900 |
| 2019-13 | 1051 | 3904287 |
| 2019-14 | 1057 | 4309552 |
| 2019-15 | 1053 | 4676142 |
| 2019-16 | 1071 | 4897571 |
| 2019-17 | 1086 | 5194951 |
| 2019-18 | 1097 | 4291125 |
| 2019-19 | 1100 | 4127173 |
| 2019-20 | 1127 | 4065942 |
| 2019-21 | 1125 | 3623816 |
| 2019-22 | 1127 | 1523581 |
| 2019-23 | 1122 | 1822741 |
| 2019-24 | 1241 | 1480971 |
| 2019-25 | 1245 | 1700950 |
| 2019-26 | 1235 | 1492285 |
| 2019-27 | 1235 | 1098727 |
| 2019-28 | 1233 | 941500 |
| 2019-29 | 1230 | 893052 |
| 2019-30 | 1232 | 1025655 |
| 2019-31 | 1239 | 1186058 |
| 2019-32 | 1228 | 1189090 |
| 2019-33 | 1230 | 1106885 |
| 2019-34 | 1230 | 1274547 |
| 2019-35 | 1229 | 1322772 |
| 2019-36 | 1229 | 671083 |
| 2019-37 | 1225 | 1216611 |
| 2019-38 | 1228 | 1091560 |
| 2019-39 | 1226 | 1208336 |
| 2019-40 | 1228 | 935742 |
| 2019-41 | 1224 | 802683 |
| 2019-42 | 1230 | 1011143 |
| 2019-43 | 1234 | 1060517 |
| 2019-44 | 554 | 273411 |
| 2019-45 | 497 | 167728 |
| 2019-46 | 476 | 136748 |
| 2019-47 | 410 | 0 |
| 2019-48 | 442 | 0 |
| 2019-49 | 427 | 0 |
| 2019-50 | 368 | 0 |
| 2019-51 | 435 | 0 |
| 2019-52 | 457 | 0 |
| 2019-53 | 282 | 34 |
| 2020-01 | 355 | 0 |
| 2020-02 | 525 | 0 |
| 2020-03 | 537 | 0 |
| 2020-04 | 528 | 0 |
| 2020-05 | 563 | 0 |
| 2020-06 | 587 | 0 |
| 2020-07 | 620 | 0 |
| 2020-08 | 607 | 0 |
| 2020-09 | 594 | 0 |
| 2020-10 | 664 | 0 |
| 2020-11 | 679 | 0 |
| 2020-12 | 698 | 0 |
| 2020-13 | 724 | 0 |
| 2020-14 | 707 | 0 |
| 2020-15 | 709 | 0 |
| 2020-16 | 731 | 0 |
| 2020-17 | 710 | 0 |
| 2020-18 | 735 | 0 |
| 2020-19 | 714 | 0 |
| 2020-20 | 686 | 0 |
| 2020-21 | 700 | 0 |
| 2020-22 | 555 | 0 |
| 2020-23 | 612 | 0 |
| 2020-24 | 632 | 0 |
| 2020-25 | 647 | 0 |
| 2020-26 | 622 | 0 |
| 2020-27 | 580 | 0 |
| 2020-28 | 547 | 0 |
| 2020-29 | 559 | 0 |
| 2020-30 | 531 | 0 |
| 2020-31 | 577 | 0 |
| 2020-32 | 583 | 0 |
| 2020-33 | 561 | 0 |
| 2020-34 | 618 | 0 |
| 2020-35 | 620 | 0 |
| 2020-36 | 442 | 0 |
| 2020-37 | 525 | 0 |
| 2020-38 | 528 | 0 |
| 2020-39 | 517 | 0 |
| 2020-40 | 504 | 0 |
| 2020-41 | 462 | 0 |
| 2020-42 | 483 | 0 |
| 2020-43 | 487 | 0 |
| 2020-44 | 377 | 0 |
| 2020-45 | 42 | 0 |
shipped_agg <- shipped_agg%>%
filter(as.integer(Date) %in% c(1:255))%>%
droplevels
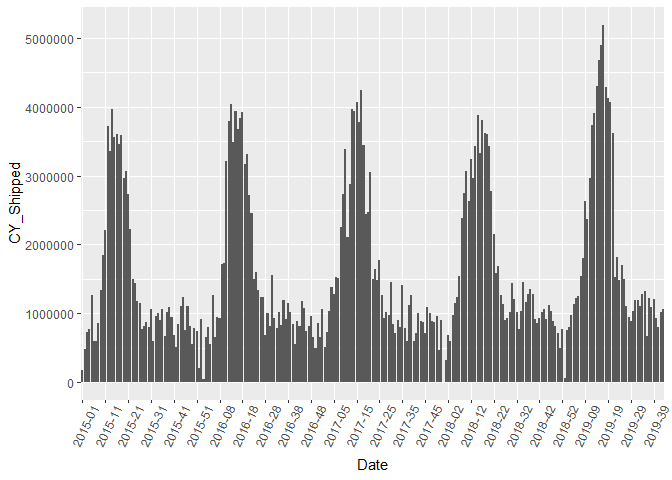
Let’s check it out again. Looks good!
my_breaks <- seq(1,length(unique(shipped_agg$Date)),by=10)
ggplot(shipped_agg, aes(x = Date, y=CY_Shipped )) +
geom_bar(stat="identity") +
theme(axis.text.x = element_text(angle=65, vjust=0.6))+
scale_x_discrete(
breaks=levels(shipped_agg$Date)[my_breaks])
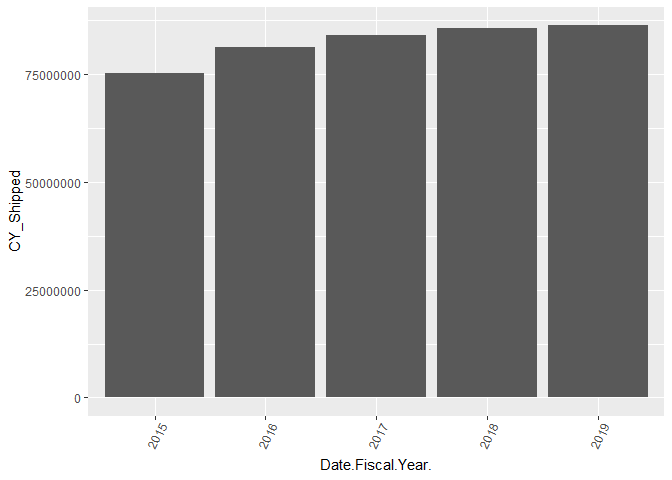
By Year
ggplot(shipped_agg, aes(x = Date.Fiscal.Year., y=CY_Shipped )) +
geom_bar(stat="identity") +
theme(axis.text.x = element_text(angle=65, vjust=0.6))
By Week
ggplot(shipped_agg, aes(x = Date.Fiscal.Week. , y= CY_Shipped)) +
geom_bar(stat="identity") +
theme(axis.text.x = element_text(angle=65, vjust=0.6))
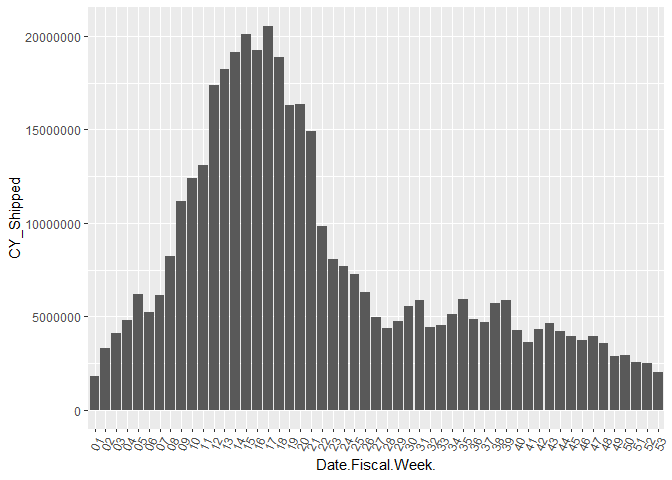
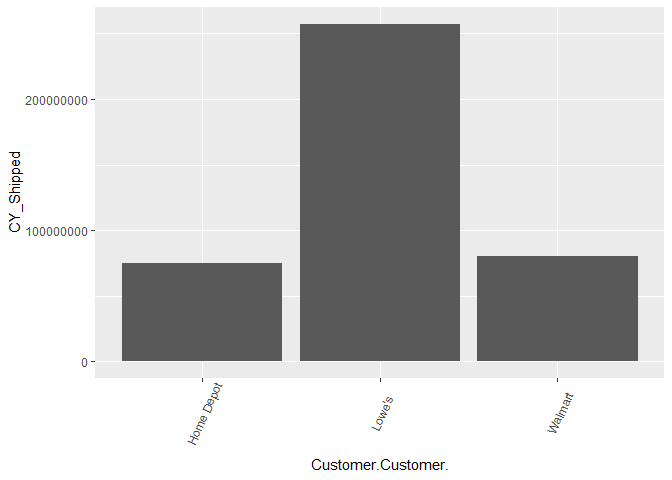
By Customer
ggplot(shipped_agg, aes(x = Customer.Customer. , y= CY_Shipped)) +
geom_bar(stat="identity") +
theme(axis.text.x = element_text(angle=65, vjust=0.6))
By Store Sub Region
ggplot(shipped_agg, aes(x = Store.Sub.Region. , y= CY_Shipped)) +
geom_bar(stat="identity") +
theme(axis.text.x = element_text(angle=65, vjust=0.6))
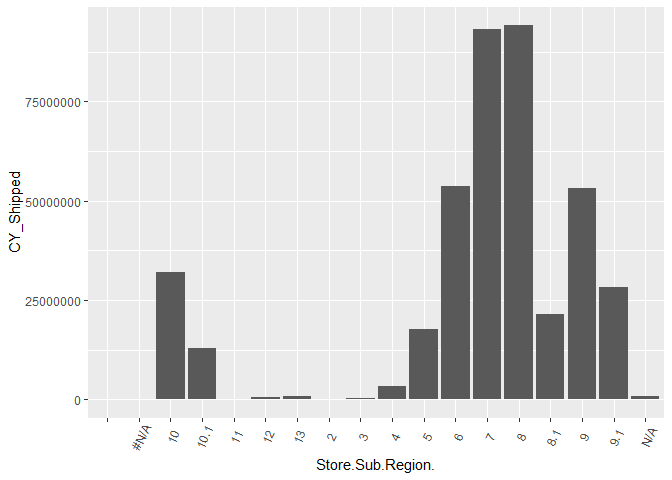
It looks like we need to get rid of blank and n/a levels in Store Region
kable(shipped_agg%>%
group_by(Store.Sub.Region.)%>%
summarize(count=n(),
total = sum(CY_Shipped),
ave=mean(CY_Shipped)))%>%
kable_styling() %>%
scroll_box(width = "500px", height = "200px")
| Store.Sub.Region. | count | total | ave |
|---|---|---|---|
| 157 | 0 | 0.000000 | |
| #N/A | 174 | 0 | 0.000000 |
| 10 | 24832 | 32071188 | 1291.526579 |
| 10.1 | 22568 | 12992922 | 575.723236 |
| 11 | 7575 | 136303 | 17.993795 |
| 12 | 6878 | 540728 | 78.617040 |
| 13 | 7092 | 797166 | 112.403553 |
| 2 | 707 | 1187 | 1.678925 |
| 3 | 10708 | 202581 | 18.918659 |
| 4 | 17334 | 3433286 | 198.066574 |
| 5 | 19491 | 17632493 | 904.647940 |
| 6 | 22677 | 53715734 | 2368.731931 |
| 7 | 27946 | 93250596 | 3336.813712 |
| 8 | 28444 | 94140291 | 3309.671319 |
| 8.1 | 24132 | 21391450 | 886.435024 |
| 9 | 26022 | 53115353 | 2041.171048 |
| 9.1 | 23708 | 28201860 | 1189.550363 |
| N/A | 12238 | 795341 | 64.989459 |
shipped_agg <- shipped_agg%>%
filter(!Store.Sub.Region. %in% c("","#N/A",'2'))%>%
droplevels
By Product Category
ggplot(shipped_agg, aes(x = Product.Category. , y= CY_Shipped)) +
geom_bar(stat="identity") +
theme(axis.text.x = element_text(angle=65, vjust=0.6))
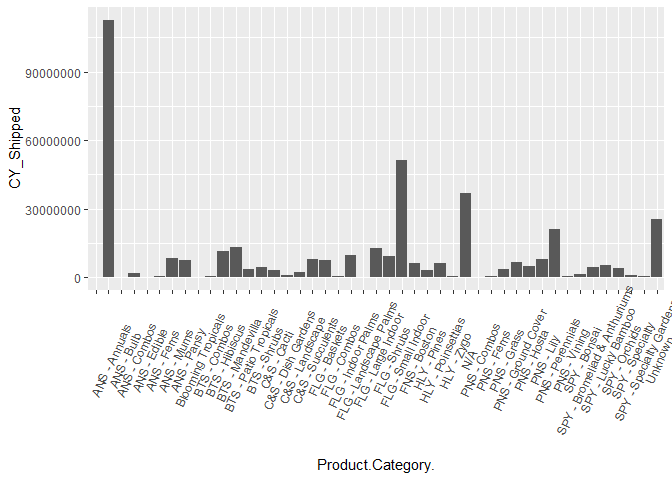
It looks like we need to get rid of a blank level in Product Category
kable(shipped_agg%>%
group_by(Product.Category.)%>%
summarize(count=n(),
total = sum(CY_Shipped)))%>%
kable_styling() %>%
scroll_box(width = "500px", height = "200px")
| Product.Category. | count | total |
|---|---|---|
| 130 | 0 | |
| ANS - Annuals | 5255 | 112779933 |
| ANS - Bulb | 1236 | 160781 |
| ANS - Combos | 3740 | 1770680 |
| ANS - Edible | 1933 | 42887 |
| ANS - Ferns | 2283 | 511271 |
| ANS - Mums | 4079 | 8451513 |
| ANS - Pansy | 2914 | 7729403 |
| Blooming Tropicals | 20 | 918 |
| BTS - Combos | 6999 | 686589 |
| BTS - Hibiscus | 9239 | 11669884 |
| BTS - Mandevilla | 9284 | 13060827 |
| BTS - Patio Tropicals | 9039 | 3507474 |
| BTS - Shrubs | 8668 | 4502993 |
| C&S - Cacti | 9337 | 3014441 |
| C&S - Dish Gardens | 8032 | 978072 |
| C&S - Landscape | 8582 | 2410353 |
| C&S - Succulents | 8446 | 8130707 |
| FLG - Baskets | 9592 | 7747728 |
| FLG - Combos | 7848 | 602276 |
| FLG - Indoor Palms | 9671 | 9658999 |
| FLG - Landscape Palms | 6601 | 220809 |
| FLG - Large Indoor | 9704 | 13004025 |
| FLG - Shrubs | 9506 | 9114587 |
| FLG - Small Indoor | 9772 | 51483707 |
| FNS - Boston | 8684 | 6270254 |
| HLY - Pines | 8089 | 3220867 |
| HLY - Poinsettias | 3479 | 6173471 |
| HLY - Zygo | 5080 | 472828 |
| N/A | 9382 | 36745837 |
| PNS - Combos | 2700 | 191704 |
| PNS - Ferns | 1975 | 691902 |
| PNS - Grass | 3276 | 3640043 |
| PNS - Ground Cover | 2799 | 6649366 |
| PNS - Hosta | 2244 | 4909560 |
| PNS - Lily | 5154 | 7984826 |
| PNS - Perennials | 5218 | 21069047 |
| PNS - Vining | 1643 | 533286 |
| SPY - Bonsai | 9354 | 1624706 |
| SPY - Bromeliad & Anthuriums | 9403 | 4665225 |
| SPY - Lucky Bamboo | 9420 | 5440838 |
| SPY - Orchids | 7440 | 3881219 |
| SPY - Specialty | 9173 | 1060674 |
| SPY - Specialty Gardens | 8338 | 583502 |
| Unknown | 6884 | 25367280 |
shipped_agg <- shipped_agg%>%
filter(!Product.Category. %in% c("","Blooming Tropicals"))%>%
droplevels
A very important step in this project was to create lagged version of all my Shipping, Sales, and COGS data. First, I must create a data frame that has a row for every unique combination of Customer/Store Sub Region/Product Category/Date. Then, I need to join this data back to my original data set so that the lag function is able to correctly create a lagged number. Finally, I created 4 lagged variables for each of the Shipping, Sales, and COGS variables.
lagged_df = expand.grid(
Customer.Customer. = sort(unique(shipped_agg$Customer.Customer.)),
Store.Sub.Region. = sort(unique(shipped_agg$Store.Sub.Region.)),
Product.Category. = sort(unique(shipped_agg$Product.Category.)),
Date = sort(unique(shipped_agg$Date))) %>%
left_join(shipped_agg, by = c("Customer.Customer.","Store.Sub.Region.","Product.Category.","Date")) %>%
arrange(Customer.Customer.,Store.Sub.Region.,Product.Category.,Date) %>%
group_by(Customer.Customer.,Store.Sub.Region.,Product.Category.) %>%
mutate(CY_Shipped_Lag1 = lag(CY_Shipped,n = 1),
CY_Shipped_Lag2 = lag(CY_Shipped,n = 2),
CY_Shipped_Lag3 = lag(CY_Shipped,n = 3),
CY_Shipped_Lag4 = lag(CY_Shipped,n = 4),
PY_Shipped_Lag1 = lag(PY_Shipped,n = 1),
PY_Shipped_Lag2 = lag(PY_Shipped,n = 2),
PY_Shipped_Lag3 = lag(PY_Shipped,n = 3),
PY_Shipped_Lag4 = lag(PY_Shipped,n = 4),
Sales_Lag1 = lag(Sales_Amt,n = 1),
Sales_Lag2 = lag(Sales_Amt,n = 2),
Sales_Lag3 = lag(Sales_Amt,n = 3),
Sales_Lag4 = lag(Sales_Amt,n = 4),
COGS_Lag1 = lag(COGS,n = 1),
COGS_Lag2 = lag(COGS,n = 2),
COGS_Lag3 = lag(COGS,n = 3),
COGS_Lag4 = lag(COGS,n = 4)) %>%
ungroup()
Determine how many null values are in the new data set. Year, Week, Sales, and Cogs are all missing the same data from the join in the previous step.
colSums(sapply(lagged_df,is.na))
## Customer.Customer. Store.Sub.Region. Product.Category.
## 0 0 0
## Date Date.Fiscal.Year. Date.Fiscal.Week.
## 0 211930 211930
## CY_Shipped PY_Shipped COGS
## 211930 211930 211930
## Sales_Qty Sales_Amt CY_Shipped_Lag1
## 211930 211930 213146
## CY_Shipped_Lag2 CY_Shipped_Lag3 CY_Shipped_Lag4
## 214359 215564 216773
## PY_Shipped_Lag1 PY_Shipped_Lag2 PY_Shipped_Lag3
## 213146 214359 215564
## PY_Shipped_Lag4 Sales_Lag1 Sales_Lag2
## 216773 213146 214359
## Sales_Lag3 Sales_Lag4 COGS_Lag1
## 215564 216773 213146
## COGS_Lag2 COGS_Lag3 COGS_Lag4
## 214359 215564 216773
Drop the missing values that were created during the join.
lagged_df <- lagged_df[!is.na(lagged_df$Date.Fiscal.Week.),]
Drop the missing values that were created by lagging
lagged_df <- as.data.frame(lagged_df[complete.cases(lagged_df),])
lagged_df <- lagged_df%>%
select(-c("Date"))
colSums(sapply(lagged_df,is.na))
## Customer.Customer. Store.Sub.Region. Product.Category.
## 0 0 0
## Date.Fiscal.Year. Date.Fiscal.Week. CY_Shipped
## 0 0 0
## PY_Shipped COGS Sales_Qty
## 0 0 0
## Sales_Amt CY_Shipped_Lag1 CY_Shipped_Lag2
## 0 0 0
## CY_Shipped_Lag3 CY_Shipped_Lag4 PY_Shipped_Lag1
## 0 0 0
## PY_Shipped_Lag2 PY_Shipped_Lag3 PY_Shipped_Lag4
## 0 0 0
## Sales_Lag1 Sales_Lag2 Sales_Lag3
## 0 0 0
## Sales_Lag4 COGS_Lag1 COGS_Lag2
## 0 0 0
## COGS_Lag3 COGS_Lag4
## 0 0
Correlations
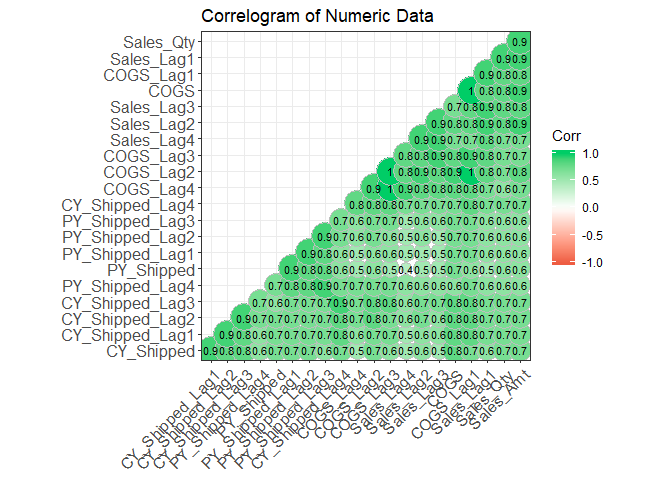
I want to look to see how correlated the numeric variables are currently. This will give me a feel for what types of models that I can use on this data set.
corr <- round(cor(lagged_df[6:26]), 1)
# Plot
library('ggcorrplot')
ggcorrplot(corr, hc.order = TRUE,
type = "lower",
lab = TRUE,
lab_size = 3,
method="circle",
colors = c("tomato2", "white", "springgreen3"),
title="Correlogram of Numeric Data",
ggtheme=theme_bw)
Model creation
First, I need to scale all of the data so that I can determine the most important features later. Then I dummy all factor variables and create a test and training set.
Scale data
preprocessParams<-preProcess(lagged_df, method = c("center", "scale"))
lagged_df <- predict(preprocessParams, lagged_df)
Dummy factor variables
factor_vars <- names(lagged_df)[which(sapply(lagged_df,is.factor))]
dummies <- dummyVars(~.,lagged_df[factor_vars])
hot_coded <- predict(dummies,lagged_df[factor_vars])
numeric_vars <- names(lagged_df)[which(sapply(lagged_df,is.numeric))]
num_df <- lagged_df[numeric_vars]
model_df_onehot <- cbind(num_df,hot_coded)
Split the data based on year. 2015-2018 in the training set and 2019 in the validation test set.
trainSet <- model_df_onehot[model_df_onehot$Date.Fiscal.Year..2019=='0',]
testSet <- model_df_onehot[model_df_onehot$Date.Fiscal.Year..2019=='1',]
Drop the Year variables so that we don’t get any errors when running the models
trainSet <- trainSet%>%
select(-c(Date.Fiscal.Year..2015,Date.Fiscal.Year..2016, Date.Fiscal.Year..2017,Date.Fiscal.Year..2018,Date.Fiscal.Year..2019))
testSet <- testSet%>%
select(-c(Date.Fiscal.Year..2015,Date.Fiscal.Year..2016, Date.Fiscal.Year..2017,Date.Fiscal.Year..2018,Date.Fiscal.Year..2019))
Create three models. A lasso,ridge, and linear model.
TARGET.VAR <- "CY_Shipped"
candidate.features <- setdiff(names(trainSet),c(TARGET.VAR))
set.seed(123)
control <- trainControl(method="cv",
number=5)
parameters <- c(seq(0.1, 2, by =0.1) , seq(2, 5, 0.5) , seq(5, 100, 1))
lasso<-train(x= trainSet[,candidate.features],
y = trainSet[,TARGET.VAR],
method = 'glmnet',
trControl=control,
tuneGrid = expand.grid(alpha = 1, lambda = parameters) ,
metric = "RMSE")
ridge<-train(x= trainSet[,candidate.features],
y = trainSet[,TARGET.VAR],
method = 'glmnet',
trControl=control,
tuneGrid = expand.grid(alpha = 0, lambda = parameters),
metric = "RMSE")
linear<-train(x= trainSet[,candidate.features],
y = trainSet[,TARGET.VAR],
trControl=control,
method = 'lm',
metric = "RMSE")
Model Results
It looks like all the models did fairly well with the training data set with the Linear model outperforming in both RMSE and R-squared.
model_list <- list(lasso=lasso,ridge=ridge,linear=linear)
summary(resamples(model_list))
##
## Call:
## summary.resamples(object = resamples(model_list))
##
## Models: lasso, ridge, linear
## Number of resamples: 5
##
## MAE
## Min. 1st Qu. Median Mean 3rd Qu. Max.
## lasso 0.09742777 0.09827569 0.09859958 0.09906175 0.09948065 0.10152508
## ridge 0.09296833 0.09415144 0.09491919 0.09456453 0.09495086 0.09583285
## linear 0.09348050 0.09440606 0.09516680 0.09531440 0.09595117 0.09756750
## NA's
## lasso 0
## ridge 0
## linear 0
##
## RMSE
## Min. 1st Qu. Median Mean 3rd Qu. Max. NA's
## lasso 0.4092295 0.4208671 0.4242020 0.4268525 0.4355914 0.4443723 0
## ridge 0.3787219 0.3960977 0.3982898 0.4045070 0.4206382 0.4287874 0
## linear 0.3891585 0.3911724 0.3996394 0.4005655 0.4110404 0.4118168 0
##
## Rsquared
## Min. 1st Qu. Median Mean 3rd Qu. Max. NA's
## lasso 0.7877135 0.7920025 0.8000212 0.8052528 0.8015361 0.8449907 0
## ridge 0.7910908 0.8047406 0.8121815 0.8145672 0.8283172 0.8365058 0
## linear 0.8003835 0.8091260 0.8156204 0.8174309 0.8301179 0.8319066 0
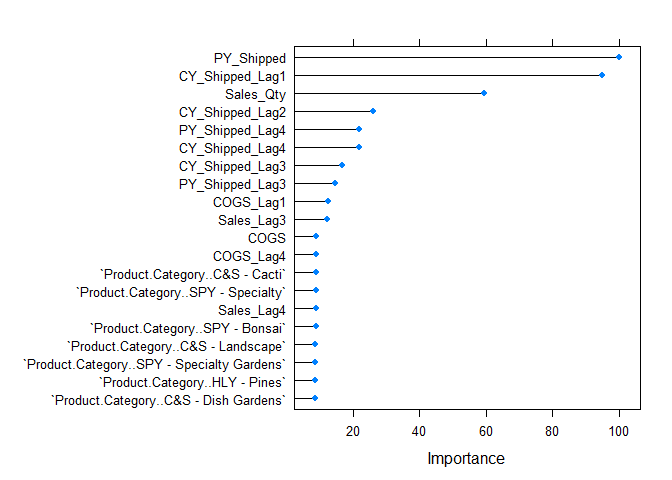
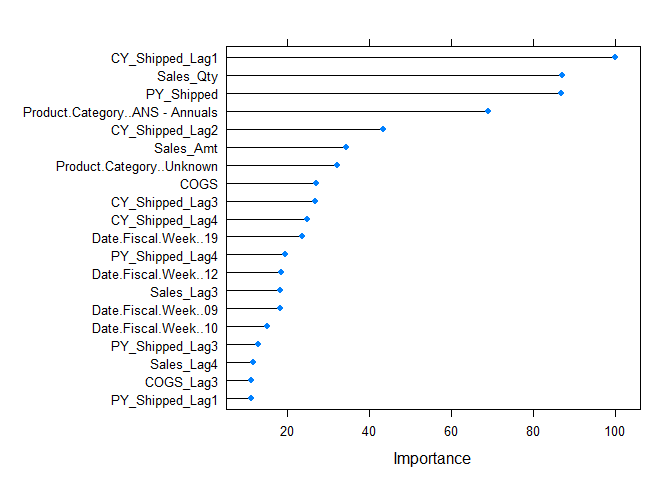
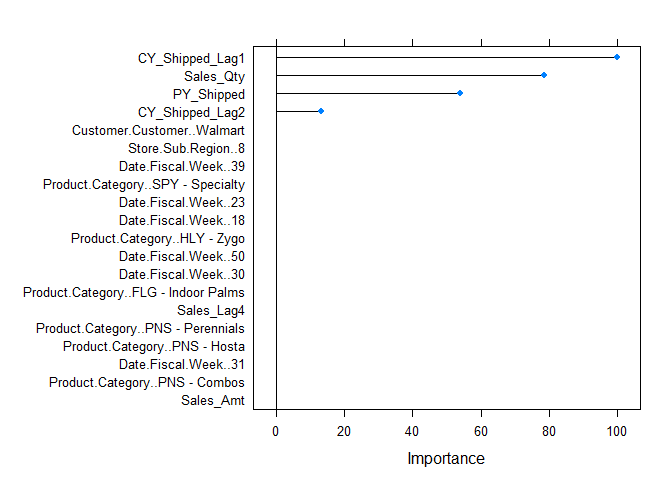
Variable Importance
Both the linear and ridge models had similar variables they deemed important. However, the lasso regression model tossed out all but 4 variables.This is due to multicollinearity in the data as seen in the correlation plot above. I will testing the data on more algorithms in a separte markdown.
plot(varImp(ridge),top=20)
plot(varImp(lasso),top=20)
plot(varImp(linear),top=20)